

Discover
Visualize rapid, validated insights through real-world data.

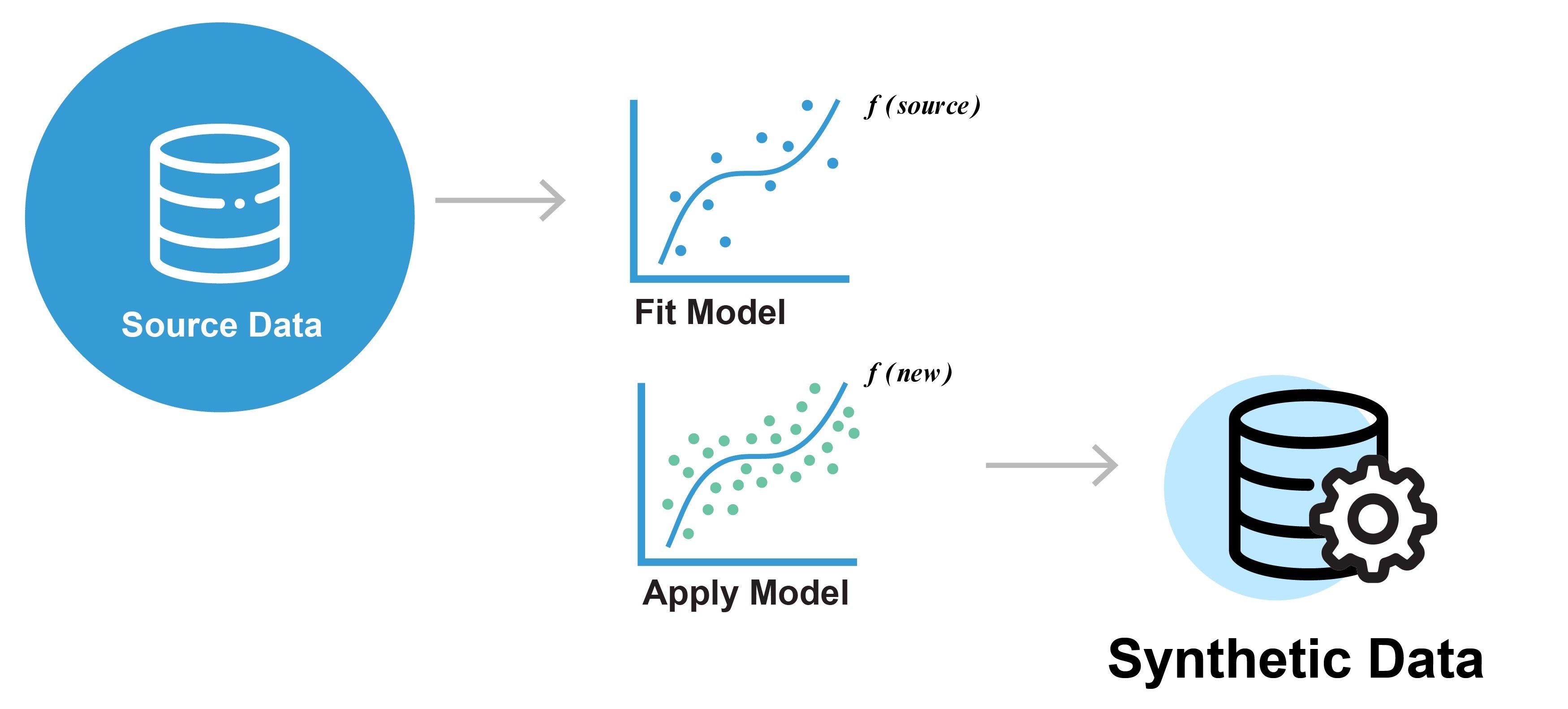
The real data would be the original personally identifiable datasets that are available, for example, health records, financial transaction data, or sales data. This is the data that we want to create non-identifiable versions or synthetic versions of.
We take that data and build a model that captures the statistical properties and the patterns in that data. This is typically a machine learning model that is built. These types of models have become quite good at capturing the subtle patterns in complex datasets. These models are also called generative models.
Once a model is built, we can then use that model to generate new data. This is the synthetic data. So the new data that is generated actually comes from the model that was fitted. There will not be a one-to-one mapping between the synthetic records and the records in the source data. This is why synthetic data can be quite protective against identity disclosure and other privacy risks.
You have probably already seen synthetic data in the context of deep fakes. These are realistic computer-generated images. The fake people that they create look quite realistic, and so as you can see the technology has become quite good.

The same principles apply to structured data, which is the type of data that we are interested in.
Therefore the goal with synthetic data is to generate new records that look realistic, but in the context of datasets that include personal information, we are also interested in preserving the privacy of individuals in the real data. So synthetic data generation needs to balance preserving privacy with generating high-utility data that looks realistic.
A common question about synthetic data generation is whether you need to know how the data will be used in advance. We assume here that "use" means some form of data analysis (e.g., regression or machine learning algorithm). This means is the data synthesis specific to the analysis that will be performed on the dataset?
The general answer is no. The basic idea is that the data synthesis process is capturing many, or almost all (it is never going to be "all" since that cannot be guaranteed except for trivial cases) of the patterns in the data that the synthetic data can be used in arbitrary ways. Of course there are limitations to that. For example, very rare events may not be captured well by the generative model. However, in general, the generative models have been good at capturing the patterns in the data.
Therefore, when synthetic data is generated no a priori assumptions are made about the eventual data uses.
One other question that often comes up is about how large the source datasets need to be or can be. This question can be interpreted in two different ways:
What is the minimal dataset size for SDG to work?
Because at Aetion many of our initial projects were with clinical trial data, we have developed generative models that work well with small datasets. This means datasets with say 100 to 200 patients. If there are fewer than a 100 patients or so it will be difficult to build a generative model.
An important factor to consider is the number of variables in the dataset. It is easier to create a generative model with a dataset having 500 patients and 10 variables than a dataset having 500 patients and 500 variables. In practice for the latter case, many of these variables will be redundant, derived, or have many missing values. Therefore, it is often not as extreme as it sounds. But the point is that the number of variables is an important consideration.
The statistical machine learning techniques that work very well for large datasets, like deep learning methods, will generally not do well on small datasets. Therefore we need to have a toolbox of different techniques that we apply depending on the nature of the data.
What is the largest source dataset that can be synthesized?
The answer to this question will partially depend on the computing capacity that is available to the SDG software. The creation of a generative model is computationally demanding. And depending on the methods used, the availability of GPUs will have an impact on the answer to that question. Also the amount of memory will be important (on the CPUs and GPUs). The system adapts the computations but the hardware will place limits as well.
There are techniques to handle large datasets in SDG. They cover both algorithmic techniques and software and systems engineering techniques. These approaches have been implemented in our Aetion® Generate software. The system distributes computations across (virtual) machines and therefore can scale in that way quite easily.
Can synthesis handle missing data?
Real data will have missingness in it. The missingness may be at random (which is a common assumption and probably not met that often in practice). Missingness patterns are important in that they may have meaning by themselves (e.g., certain patients do not or cannot provide certain data), or they may be structural.
The way our SDG engine works is that it models missingness in the original data. This means that a specific model (or set of models) is built to understand the conditions under which missingness occurs. These learned patterns are then reproduced at the output end. Therefore, the synthetic data would have similar patterns of missingness as the original data. Nothing specific needs to be done by the analyst to ensure that this occurs, as this is handled automatically by the software.
The original data structure means the field types, field names, tables, and relationships among the tables in the source data. These relationships are retained in the output synthetic data. This means that the synthetic data will look very similar to the original dataset structurally.
The format of the dataset is determined by the end-user of the software. For example, the end user may send the synthetic data to a different type of database or file format than the original dataset. Of course, the format of the synthetic data can be set to be the same as the original dataset.
Such structural similarity is very important for some use cases. For example, if the use case is to perform software testing then the exact structure and format as the original data is an important requirement.