

Discover
Visualize rapid, validated insights through real-world data.

Aetion® Generate, formerly Replica Synthesis, is Aetion’s scalable enterprise software that allows users to create synthetic data. The main features of the product are as follows:
The overall architecture of the product is shown below. The software allows the computations to scale in a cluster to accommodate larger and more complex datasets.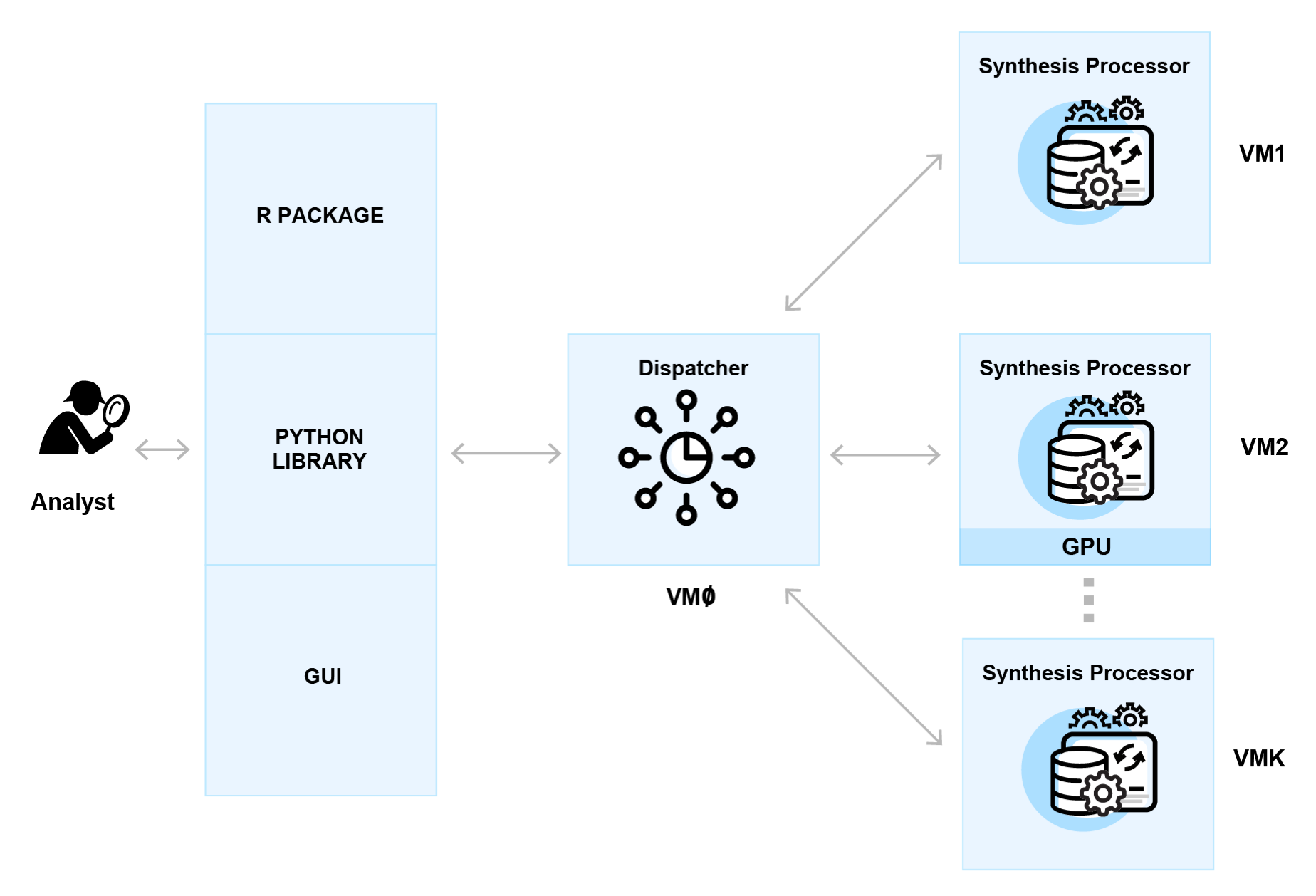
This question has multiple layers and it is best to parse them out and address them separately.
Is manual intervention needed to synthesize data?
We have worked very hard to maximize the automation in Generate. The software does quite a bit of automated discovery of the data characteristics and data shaping to make it ready for synthesis, and then reverses any shaping at the back-end of the whole process.
The user, of course, has to load data or connect to data sources. If any cohorts need to be defined, then that is also a necessary task. However, in many situations, the synthesis process itself is automated, including all of the necessary hyperparameter tuning needed for training the generative models. This applies when using the GUI or when using the different APIs (R or Python) to perform SDG.
However, there is also an option to tweak this automated process for advanced users. While the automated pre-processing works very well, there may be cases where some adjustments are needed. Generate also provides this capability, but we hope you never have to use it.
By design, very little knowledge about SDG is required to use Generate. Of course, the user needs to know the data and how to access their data sources. The user will need to understand the data domain to be able to define meaningful cohorts. But training on SDG is not necessary as that complexity is hidden from the user in Generate.
The on-line help is also a great resource for using the software.
We have clients who have done exactly that. Because of the high level of automation, Generate can be inserted in data pipelines to convert the original datasets into synthetic variants. This can be done by training a generative model for every data cut that comes through the pipeline. For example, when a dataset request is approved, the original dataset can be sent to Generate, and the resultant synthetic dataset is then forwarded to the analyst to work on.