

Discover
Visualize rapid, validated insights through real-world data.

By Lucy Mosquera and Abhik Das
Posted on: July 5, 2022
Access to healthcare data to accelerate research remains a challenge. Even during the unprecedented Covid-19 pandemic, sharing de-identified individual-level datasets with the research community was a difficult process. One major concern among data custodians is privacy risk. However, there has been no reliable measure of such re-identification risks until now.
Re-identification risk is defined as the probability of an adversary correctly matching a record in a dataset with a real person. Many existing estimators in the literature do not model actual adversarial attacks, and therefore provide only a proxy for risk. In our recent publication in PLOS ONE, we evaluate the performance of a new re-identification risk estimator we have developed based on synthetic data generation (SDG) methods against 3 estimators widely accepted in the current literature. We also demonstrated the utility of this estimator to de-identify a Covid-19 dataset and calculate the re-identification risk of matching against a public registry.
Typically, re-identification risk is estimated on a dataset prior to sharing. This dataset is referred to as a microdata sample, as in practice, this dataset is part of a larger population. The general idea of an adversarial attack is that an adversary tries to match records from the microdata sample to individuals in the population using a set of variables called quasi-identifiers. Quasi-identifiers are traits that may be known to the adversary that can be combined to uniquely identify individuals in the population. Typical examples of quasi-identifiers are gender, date of birth, race, etc. If both the microdata and the population data are available to data custodians, the probability that records can be re-identified can be calculated empirically. However, the population data is rarely available to data custodians, so re-identification risk must be estimated.
Existing estimators use a variety of different techniques such as the uniqueness of a population or Bayesian approaches to calculate this risk. Our new estimator leverages our data synthesis technology to simulate the unavailable population dataset and we can then empirically calculate the risk more accurately. The population is synthesized by fitting copula models on the quasi-identifiers in the microdata sample. The fit copula models are then used to generate a synthetic population from where we sample a synthetic microdata sample. Then we calculate the risk of matching an individual in the synthetic microdata sample to a record in the synthetic population. Copulas are powerful models that link univariate marginal distributions to form a multivariate distribution that captures relationships between variables. Our proposed estimate is an average of the risks estimated by 2 copula methods – Gaussian and d-Vine.
For our recently-published analysis, we used 4 datasets – a) Adults from the UCI machine learning repository b) a Texas hospital discharge dataset c) the Washington State 2007 hospital discharge dataset d) the Nexoid dataset which is an online Covid 19 survey. We evaluated 3 existing estimators: the entropy estimator (entropy), the hypothesis testing estimator (hypothesis test), the Benedetti-Franconi estimator (Italian), and 3 variants of synthesis-based estimators: the Gaussian copula estimator (gaussian copula), the d-vine copula (d-vine copula) and the average of these two copula estimators (average).
To conduct the study, simulations were done by varying selected number of quasi-identifiers and sampling fractions (0.05, 0.3, 0.7). The alteration of quasi-identifiers helped in modelling datasets of varying complexity and re-identification risks. Different sampling fractions helped in understanding the effect of the ratio between sample size to synthesized population on estimated risk scores. A total of 1000 data points were generated using the constructed synthetic sample and population datasets. The difference between the estimated risk score and the true risk score was computed to be estimate error. The box-whisker plot in Figure 1 compares the estimate error for the six estimators on the Texas dataset when sampling fraction is 0.3. 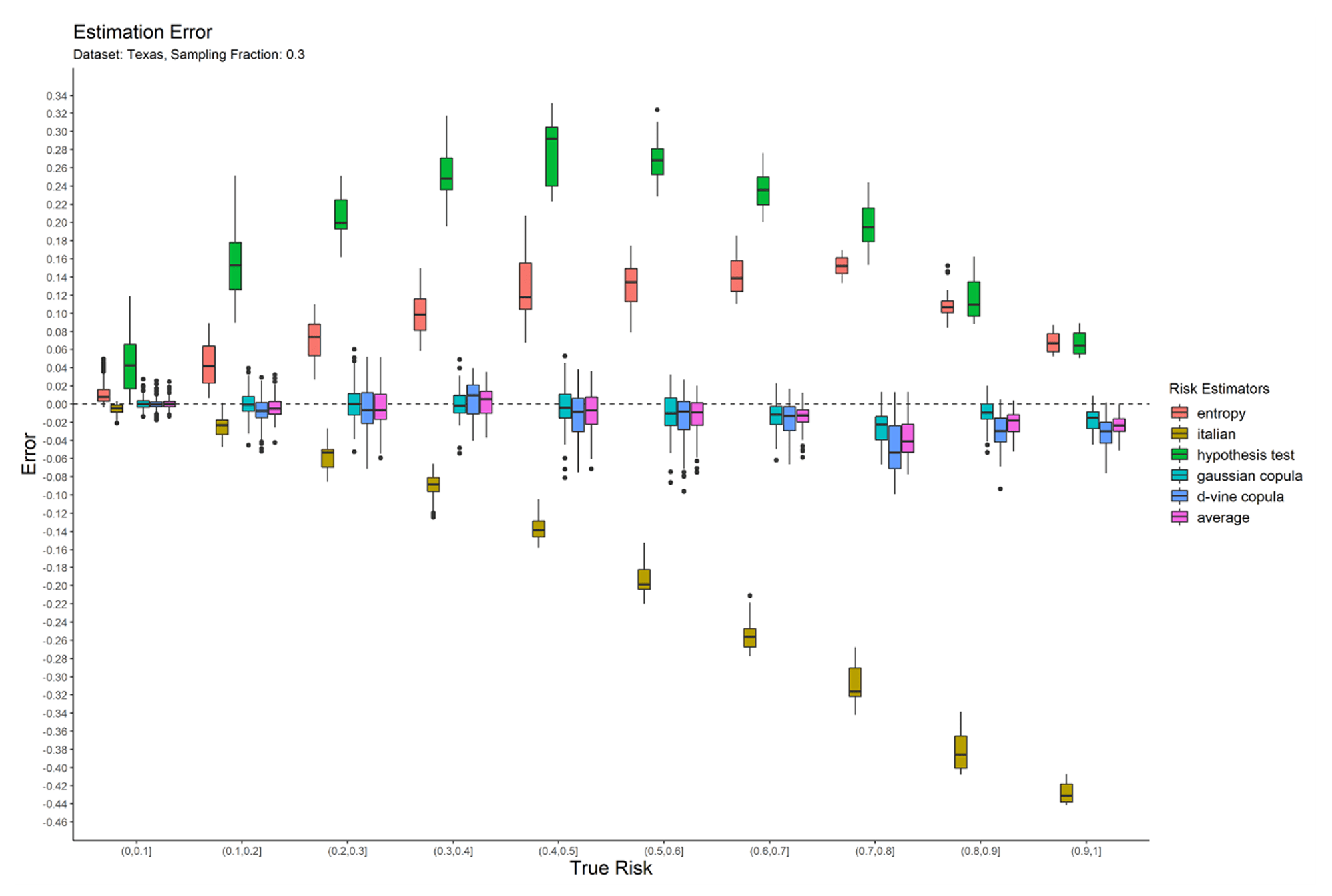 Figure 1: Sampling fraction of 0.3 for Texas dataset
Figure 1: Sampling fraction of 0.3 for Texas dataset
Across all datasets and different simulation settings, our average copula estimator performs the best and keeps the error to within a 5% tolerance limit. In contrast, the entropy method consistently overestimates the risk and the Italian method underestimates the risk. The hypothesis estimator overestimates for high sampling fraction and underestimates for lower sampling fractions.
These results show that this method of creating a synthetic population from the microdata and using that population to empirically calculate the risk reliably outperforms the other risk estimators across different data sets’ sizes and varying complexity. Our new copula risk estimator achieves a high degree of accuracy and is therefore a consistent estimate of the probability of re-identification risk.
As an additional case study, we successfully used the average copula estimator to de-identify a Covid 19 dataset (flatten.ca dataset available on Physionet). The microdata contained 18,903 observations and the simulated population had a size of approx. 13M individuals. The estimated sample-to-population risk was computed as 0.0723 and population-to-sample risk was computed as 0.0009. These risk estimates are consistent and well below the widely accepted threshold of 0.09. The case study shows that the average copula estimator can be utilized to simulate a population and calculate re-identification risk estimates.
From our analysis and the case study, it can be concluded that the average copula estimator of synthesizing a population from a microdata sample, then sampling from the synthetic population to create a synthetic sample produces more accurate re-identification risk estimates than existing estimators. Our new estimator can be used to de-identify microdata samples, even when population datasets are not available.
This is another example of the usefulness and effectiveness of synthetic data generation technology in assessing and mitigating privacy risks and enabling data sharing. This novel estimator, which leverages SDG, can now be used to better assess re-identification risks in real datasets and, if the risk is deemed too high, organizations can choose to synthesize the data and use the privacy assurance functionality we have developed to measure any risk in the synthetic data to demonstrate that it is much lower than the real data.
For the detailed analysis of this study, please refer to the full article here.